Chào mừng các bạn đọc đã quay trở lại với chuỗi bài viết về Machine Learning của CLB AI. Ở bài viết trước, chúng ta đã được tìm hiểu và tiếp cận một cách tổng quát về Machine Learning với ba nhóm bài toán chính là Regression, Classification và Clustering. Để giúp bạn đọc hiểu rõ hơn Machine Learning ở góc độ toán học, ở bài viết này chúng ta sẽ cùng tìm hiểu về một thuật toán đơn giản trong bài toán Regression là Linear Regression (Hồi quy tuyến tính). Thông qua bài viết này, bạn sẽ có thể áp dụng kiến thức để xây dựng một mô hình máy học để dự đoán điểm cuối kỳ Nhập môn Lập trình, và sẽ được “nghịch” với nó để xem phong cách “học” của máy là như thế nào.
Nội dung chính
- 1 1. Bạn đang xem: Linear regression là gì Linear Regression là gì?
- 2 2. Một vài ký hiệu cần lưu ý và cách xác định input và output của bài toán.
- 3 3. Bài toán dự đoán điểm trung bình Nhập môn lập trình
- 4 4. Sử dụng thuật toán hồi quy tuyến tính để giải bài toán tính giá nhà.
- 5 5. Gradient Descent là gì?
- 6 6. Ứng dụng của Linear Regression trong thực tế
- 7 7. Tổng kết.
- 8 7. Tài liệu tham khảo
- 9 Post navigation
1.
Bạn đang xem: Linear regression là gì
Linear Regression là gì?
Linear Regression (Hồi quy tuyến tính) là một trong những thuật toán cơ bản và phổ biến nhất của Supervised Learning (Học có giám sát), trong đó đầu ra dự đoán là liên tục. Thuật toán này thích hợp để dự đoán các giá trị đầu ra là các đại lượng liên tục như doanh số hay giá cả thay vì cố gắng phân loại chúng thành các đại lượng rời rạc như màu sắc và chất liệu của quần áo, hay xác định đối tượng trong một bức ảnh là mèo hay chó, …

Thử lấy ví dụ sau: bạn đang có điểm thành phần về các môn như Nhập môn lập trình, OOP, Giải tích,… và điều bạn đang cần là tính ra điểm trung bình cuối kỳ của mình. Rất đơn giản, bạn sẽ tính được chứ? Tất nhiên rồi! Bạn chỉ cần áp công thức tính điểm trung bình vào là ra. Tiếp tục, bạn lại muốn khảo sát, thống kê lại xem điểm thi giữa kỳ Nhập môn lập trình ảnh hưởng như thế nào đến điểm cuối kỳ của các bạn trong lớp, bạn muốn xác định xem quan hệ giữa điểm thành phần và điểm cuối kỳ thì phải làm sao? Đây có lẽ là một bài toán khó đối với những bạn chưa từng làm việc với Máy học hoặc Thống kê, tuy nhiên cũng đừng vội lo lắng, hãy cùng nhau khám phá và giải quyết các thắc mắc trong bài viết này nhé!
Trong Linear Regression chúng ta sẽ gặp hai loại bài toán đó là Hồi quy đơn biến và Hồi quy đa biến. Để đơn giản thuật toán, chúng ra sẽ tìm hiểu và phân tích kỹ toán học của bài hồi quy đơn biến. Vậy hồi quy tuyến tính đơn biến là gì? Univariate Linear Regression (hồi quy tuyến tính đơn biến) chính là mối quan hệ giữa hai biến số liên tục trên trục hoành \(x\) và trên trục tung \(y\). Phương trình hồi quy tuyến tính đơn biến có dạng như phương trình đường thẳng \( y = ax + b \) với \(x\) là biến độc lập và \(y\) là biến phụ thuộc vào \(x\). Đối với Hồi quy tuyến tính đa biến, bạn có thể hiểu một cách đơn giản là sẽ có nhiều biến độc lập \(x_1, x_2, \dots, x_n\) và nhiều hệ số \(a_1, a_2, \dots, a_n\) thay vì chỉ một biến \(x\) duy nhất.
2. Một vài ký hiệu cần lưu ý và cách xác định input và output của bài toán.
Tổng quát hơn, trong supervised learning (học có giám sát), chúng ta có một bộ dữ liệu và bộ dữ liệu này gọi là training set (tập huấn luyện).
Giả sử tất cả chúng ta có bộ tài liệu thống kê điểm giữa kỳ và điểm cuối kỳ trong Nhập môn lập trình. Khi đó, với bài toán hồi quy đơn biến này, cần tìm ra một quy mô nhận vào input là điểm giữa kỳ và output ra Dự kiến điểm cuối kỳ hợp lý nhất dựa trên mối quan hệ giữa hai cột điểm mà quy mô đó tìm được .
Để thuận tiện, ta sẽ thống nhất sử dụng một vài ký hiệu sau xuyên suốt bài viết này :\(m\): Đại diện số lượng các training example (mẫu huấn luyện). Giả sử, chúng ta có 40 dòng điểm cuối kỳ khác nhau được thu thập dựa trên điểm giữa kỳ tương ứng. Như vậy, ta có 40 mẫu huấn luyện và m bằng 40.\(x\): Để ký hiệu các input variable (biến đầu vào) cũng thường được gọi là các feature (đặc trưng). Trong hồi quy đa biến, \(x\) là một vector nhưng trong ví dụ này, \(x\) là số điểm đánh giá trong nửa học kỳ đầu – là một con số trong hồi quy đơn biến.\(y\): Để ký hiệu các biến đầu ra hay các biến mục tiêu, ở đây là điểm cuối kỳ tương ứng.\((x,y)\): đại diện một mẫu huấn luyện – training example.\(x^{(i)}, y^{(i)}\): dùng để chỉ một mẫu huấn luyện cụ thể. Giả sử, với \(i = 3\) tương ứng ta có điểm dữ liệu \(x^{(3)}, y^{(3)}\) : Số điểm cuối kỳ của bạn có thể là bao nhiêu khi điểm giữa kỳ là 8.75? Dựa vào bảng số liệu trên, tại \(y^{(3)}\), kết quả dự đoán đạt giá trị là 7.8.\ ( m \ ) : Đại diện số lượng những training example ( mẫu huấn luyện và đào tạo ). Giả sử, tất cả chúng ta có 40 dòng điểm cuối kỳ khác nhau được tích lũy dựa trên điểm giữa kỳ tương ứng. Như vậy, ta có 40 mẫu giảng dạy và m bằng 40. \ ( x \ ) : Để ký hiệu cáccũng thường được gọi là những feature ( đặc trưng ). Trong hồi quy đa biến, \ ( x \ ) là một vector nhưng trong ví dụ này, \ ( x \ ) là số điểm nhìn nhận trong nửa học kỳ đầu – là một số lượng trong hồi quy đơn biến. \ ( y \ ) : Để ký hiệu, ở đây là điểm cuối kỳ tương ứng. \ ( ( x, y ) \ ) : đại diện thay mặt một – training example. \ ( x ^ { ( i ) }, y ^ { ( i ) } \ ) : dùng để chỉ một. Giả sử, với \ ( i = 3 \ ) tương ứng ta có điểm tài liệu \ ( x ^ { ( 3 ) }, y ^ { ( 3 ) } \ ) : Số điểm cuối kỳ của bạn hoàn toàn có thể là bao nhiêu khi điểm giữa kỳ là 8.75 ? Dựa vào bảng số liệu trên, tại \ ( y ^ { ( 3 ) } \ ), tác dụng Dự kiến đạt giá trị là 7.8 .Chúng ta đã học phương trình đường thẳng \ ( y = ax + b \ ) ở bậc trung học phổ thông và hàm h – hypothesis ( giả thuyết ) cũng được trình diễn tựa như cho quy mô hồi quy tuyến tính đơn biến. Nó cũng sẽ lấy giá trị nguồn vào là x và cho ra hiệu quả đầu ra là y nhưng chỉ biến hóa những thông số kỹ thuật a và b thành \ ( \ theta_0 = b \ ) và \ ( \ theta_1 = a \ ) .Khi đó về mặt toán học, \ ( h \ ) là một ánh xạ từ \ ( x \ ) sang \ ( y \ ) :
y = h(x) = h_{\theta} (x) = b + ax = \theta_0 + \theta_1 x
3. Bài toán dự đoán điểm trung bình Nhập môn lập trình

y = h ( x ) = h_ { \ theta } ( x ) = b + ax = \ theta_0 + \ theta_1 xNguồn ảnh : NakedCode
Bây giờ, chúng ta hãy đi sâu hơn về việc giải quyết các vấn đề hồi quy đơn biến. Nhìn vào các training example (mẫu huấn luyện) được đưa ra trong hình dưới đây.
Xem thêm: Vai Trò Của Định Chế Tài Chính (Financial Institution) Là Gì? Phân Loại

Hình 1
Vậy điều gì sẽ xảy ra khi bạn cần ước lượng số điểm chính xác nhất khi đạt 7.00 điểm giữa kỳ từ thông tin trên? Hướng tiếp cận đơn giản nhất là tìm một đường thẳng (*) phù hợp với tập dữ liệu và vẽ một đường thẳng từ vị trí 7 điểm trên trục x cho đến khi nó chạm vào đường thẳng(*) vừa tìm?

Hình 2
Hãy quan sát hình trên, từ hai mẫu (4.00, 3.98) và (6.00, 5.5), ta vẽ được đường thẳng màu đỏ và từ đó tìm được hai giá trị \(\theta_0\) và \(\theta_1\) lần lượt là 0.76 và 0.94. Bây giờ, chúng ta có thể sử dụng hàm giả thuyết để dự đoán điểm cuối kỳ dựa trên điểm giữa kỳ tương ứng với giá trị 7.00 như sau: \(h(x) = 0.76x + 0.94 = 0.76*7 +0.94 = 6.26\) điểm – giá trị ước tính tương ứng với đường thẳng này.
Tuy nhiên, trong trong thực tiễn những bộ tài liệu đưa vào giảng dạy quy mô nhiều hơn gấp trăm, gấp ngàn lần và số lượng những đặc trưng cũng chênh lệch đáng kể, việc xác lập hàm tuyến tính trở nên khó khăn vất vả hơn. Sự Open của những yếu tố trên là tiền đề để máy học sinh ra, tạo ra nhiều thuật toán ship hàng cho mọi người như vận dụng thuật toán hồi quy tuyến tính và SVM ( Support Vector Machine ) trong nghiên cứu và phân tích sàn chứng khoán hay nhận dạng giọng nói bằng quy mô Markov, …
Hàm giả thuyết ở trên được xây dựng tốt hay chưa? Làm sao để hàm đó trở nên phù hợp nhất có thể? Làm thế nào bạn nhận định được điều đó? Nhờ đó hàm mất mát được tạo ra, hàm sẽ giúp bạn tính khoảng cách giữa kết quả mà hàm giả thuyết h dự đoán được so với giá trị thực sự mà ta quan sát thấy.
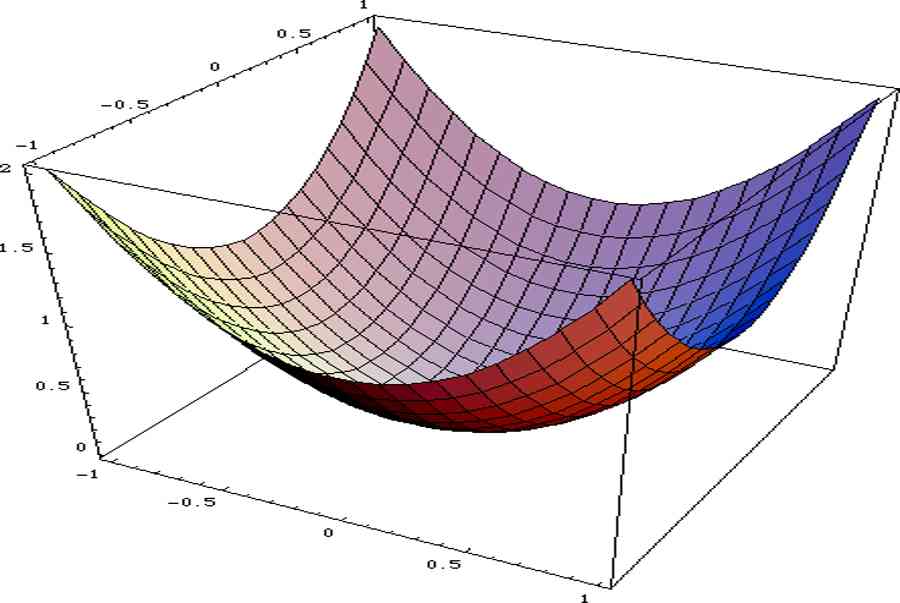
 Hình 3 : Xây dựng hàm mất mát
Hình 3 : Xây dựng hàm mất mát
Khi bạn có giá trị dự đoán là 6.26 và giá trị thực là 6.00 chúng có ý nghĩa gì? Hàm mất mát sẽ cho bạn biết sự chênh lệch giữa thực tế và giả thuyết và khi giá trị hàm này càng nhỏ, dự đoán của bạn lại càng chính xác và càng phù hợp! Bạn có mong muốn hàm mất mát đưa ra giá trị nhỏ nhất không? Đối với hồi quy tuyến tính, bạn có thể tính bình phương độ sai lệch để đánh giá sự chênh lệch giữa giá trị đưa ra bởi hàm giả thuyết và giá trị thực tế đo đạc được:
\mathcal{L}(\theta_0, \theta_1) = \frac{1}{2m} * \sum_{i=1}^{m} ^2 \\= \frac{1}{2m} * \sum_{i=1}^{m} ^2
Dưới đây là demo code của hàm mất mát của bài toán tính điểm cuối kỳ :def loss_univariate ( X, y, theta_0, theta_1 ) : h = theta_0 + theta_1 * X m = len ( X ) loss = 1 / ( 2 * m ) * np.sum ( ( y – h ) * * 2 ) return lossTừ quy mô tài liệu hình 1, ta thu được hàm giả thuyết từ điểm giữa kỳ sang điểm cuối kỳ :
\mathcal{L} = \frac{1}{2m} *
Mục tiêu của tất cả chúng ta là tối ưu hay còn gọi là đi tìm điểm cực tiểu của hàm \ ( \ mathcal { L } \ ) bên trên. Vì đây là một hàm số hai biến nên trước khi muốn tìm cực tiểu thì tất cả chúng ta cùng ôn tập lại kiến thức và kỹ năng của môn giải tích hồi năm nhất nhé ; ). Để tìm cực trị của một hàm số 2 biến \ ( f ( x, y ) \ ), ta giải hệ phương trình đạo hàm một phía sau :
Mặc dù lúc trước, khi học môn giải tích, để xác lập xem nghiệm của hệ phương trình này là điểm cực tiểu, cực lớn hay điểm yên ngựa ( điểm không phải cực tiểu cũng không phải cực lớn ) của hàm \ ( f ( x, y ) \ ), tất cả chúng ta còn phải tính \ ( f ’ _ { xx } ( x, y ), f ’ _ { yy } ( x, y ), \ ) và \ ( f ’ _ { xy } ( x, y ) \ ) và biện luận từng nghiệm, tuy nhiên vì hàm \ ( \ mathcal { L } \ ) ở đây là hàm số bậc 2, tức là nó có hình dạng như một parabol với một điểm cực tiểu duy nhất ( Hình 3 ) nên nghiệm của hệ phương trình đạo hàm cũng chính là điểm cực tiểu của hàm số \ ( \ mathcal { L } \ ). Tiếp thu kiến thức và kỹ năng kỳ quái này, ta vận dụng vào việc tìm cực tiểu của hàm mất mát như sau :
\mathcal{L}’_{\theta_0} = \frac{1}{m}* = 0
\Leftrightarrow \theta_0 + \theta_1 * \frac{(x^{(1)} + … + x^{(m)})}{m} = \frac{(y^{(1)} + … + y^{(m)})}{m}
\mathcal{L}_{\theta_1} = \frac{1}{m} = 0
\Leftrightarrow \theta_0 * \frac{(x^{(1)} + … + x^{(m)})}{m} + \theta_1 * \frac{((x^{(1)})^2 + … + (x^{(m)})^2)}{m} = \frac{(y^{(1)}x^{(1)} + … + y^{(m)}x^{(m)})}{m}
\Leftrightarrow \begin{cases} \theta_0 = \frac{(y^{(1)} + … + y^{(m)}) – \theta_1(x^{(1)} + … + x^{(m)})}{m}\\ \theta_1 = \frac{m(y^{(1)}x^{(1)} + … + y^{(m)}x^{(m)}) – (y^{(1)} + … + y^{(m)})(x^{(1)} + … + x^{(m)})}{m((x^{(1)})^2 + … + (x^{(m)})^2) – (x^{(1)} + … + x^{(m)})^2} \end{cases}
Chúng ta sẽ tính toán các giá trị trong phương trình thông qua thư viện thông dụng trong Machine Learning là Numpy, bước quan trọng nhất trong mô hình Linear Regression là đi tìm nghiệm cho bài toán. Chúng ta giải hệ phương trình của bài toán đơn biến như sau:
# Tính điểm cuối kỳ theo thetay_pred = theta_0 + theta_1*x1# Biểu diễn trên đồ thịplt.scatter(x1,x2)plt.plot(x1,y_pred.T, “r”)
Xem thêm: Đầu số 028 là mạng gì, ở đâu? Cách nhận biết nhà mạng điện thoại bàn – http://139.180.218.5

loss_univariate(X, y, theta_0, theta_1)0.27319262900804736 Từ đồ thị trên, ta thấy các điểm dữ liệu màu xanh khá gần với đường thẳng màu đỏ vậy mô hình hồi quy tuyến tính này hoạt động tốt với tập dữ liệu đã cho. Bây giờ, chúng ta kiểm tra lại kết quả hai giá trị θ0 và θ1 khi được tính bằng thư viện Scikit-Learn của Python:
Nhược điểm của phương pháp này là gì? Khi mẫu số của phương trình \(\theta_1\) ở trên bằng không thì sao? Lúc ấy, hệ phương trình trong hồi quy tuyến tính có kết quả vô nghiệm nên ta không thể tìm ra bộ trọng số lý tưởng nữa và điều chúng ta cần làm là tìm ra một lời giải đủ tốt, cần một thuật toán để tìm giá trị nhỏ nhất của hàm mất mát \(\mathcal{L}\). Chúng ta sẽ quay lại để đề cập thêm về vấn đề này trong phần tiếp theo nhé!
4. Sử dụng thuật toán hồi quy tuyến tính để giải bài toán tính giá nhà.
Với mô hình hồi quy tuyến tính đa biến, thay vì đi tìm một đường thẳng \(y=ax+b\) khớp với những điểm đã cho thì chúng ta đi tìm một mặt phẳng/siêu mặt phẳng (plane/hyperplane) trong không gian \(n\) chiều có dạng:
\theta = \begin{bmatrix} \theta_0 \\<0.3em> \theta_1 \\<0.3em> \vdots \\<0.3em> \theta_n \end{bmatrix}
làmột vector hàng chứa các dữ liệu đầu vào mở rộngvàsố 1 được thêm vào để đơn giản hóa và thuận tiện cho tính toán. Và tương tự, trong mô hình đa biến này, ta cũng có thể dựng nên hàm mất mát cho siêu mặt phẳng trên:
\mathcal{L} = \frac{1}{2m} * \left \vdots \\<0.3em> \theta_n \end{bmatrix}\right)^2 + … + \left(y^{(m)} – \begin{bmatrix} 1 & x_0^{(m)} & \cdots & x_{n}^{(m)} \end{bmatrix}\begin{bmatrix} \theta_0 \\<0.3em> \vdots \\<0.3em> \theta_n \end{bmatrix} \right)^2\right>
Các bạn dễ chứng minh được rằng, đây là công thức tổng quát cho nghiệm của hệ phương trình trên với số lượng biến θ tùy ý:
Bài toán giá nhà là một trong những ví dụ điển hình của thuật toán hồi quy đa biến này, với một bộ dữ liệu gồm 11 đặc trưng như số lượng phòng tắm, diện tích trong nhà hay cảnh quan xung quanh, … bạn sẽ tính θ như thế nào? Làm sao vận dụng thuật toán này vào trong bài toán? Với hai bộ dữ liệu gồm data_train và data_test, giờ chúng ta tiến hành train bằng phương pháp nhân ma trận nào:
# Bước 1: Tính X^T. XXtX = X.T
Xtytheta = theta# Tính định thức của X^T. Xprint(np.linalg.det(XtX)) -4.6635911969955336e-71 Để ý rằng \(-4.66*10^{-71}\), một con số cực kỳ nhỏ và gần với 0! Ở bước hai này, chúng ta không thể tính được nghịch đảo \(X^TX\) một cách chính xác do có sai số.
Liệu chúng ta đã đi đúng hướng chưa? Làm thế nào các bạn xác định được điều đó? Hãy xem sự khác biệt khi sử dụng thư viện Scikit-Learn nào:
def loss_multivariate(X, y, theta): theta = theta.reshape(-1, 1) m = len(X) # Tính hàm giả thuyết h = X
theta loss = 1/(2*m) * np.sum((y – h) ** 2) return lossVà kết quả chúng ta thu được khi so sánh hàm mát mát giữa hai phương pháp là:
Lời giải của chúng ta tính được vẫn chưa tốt bằng lời giải mà thư viện đã đưa ra, vì sẽ có trường hợp định thức của \(X^TX\) xấp xỉ 0, đồng nghĩa với việc phương trình đạo hàm vô nghiệm. Vậy chúng ta cần có một thuật toán hiệu quả và có thể dễ dàng tính được nghiệm cho bài toán này, đó chính là Gradient Descent.
*Trong Đại số Tuyến tính có một khái niệm gọi là giả nghịch đảo để tìm nghịch đảo của ma trận khi định thức của nó bằng không, tuy nhiên đó là một phần khó và sẽ được đề cập thêm ở một bài khác.
5. Gradient Descent là gì?
Trong những bài viết trước, tất cả chúng ta đã được học cách sử dụng Gradient Descent để tối ưu ( tìm điểm cực tiểu ) một hàm số bất kể, vậy hoàn toàn có thể vận dụng sáng tạo độc đáo của Gradient Descent để tìm ra bộ trọng số lý tưởng nhất cho hàm mất mát ở trên không ?Với thuật toán Gradient Descent, nếu lỗi quá cao thì thuật toán cần update những tham số có giá trị mới trong
và khi lỗi vẫn liên tục cao trong trường hợp tiếp theo, nó sẽ liên tục update những tham số với giá trị mới lần nữa. Quá trình này được lặp đi lặp lại đến khi hàm mất mát được giảm thiểu .
def gradient_descent(alpha, n): X = <4, 6, 8.75, ..., 5.7> y = <3.9, 5.5, 7.8, ..., 4.9> m = len(X) theta_0 = 0 theta_1 = 0 for _ in range (n): d_theta_0 = <> d_theta_1 = <> for i in range (m): d_theta_0.append((theta_0 +theta_1*X) – y) d_theta_1.append(((theta_0 + theta_1*X) – y) * X) theta_0 = theta_0 – alpha*(1/m)*sum(d_theta_0) theta_1 = theta_1 – alpha *(1/m)*sum(d_theta_1) return theta_0, theta_1Tóm lại, trong Gradient Descent, chúng ta hướng về vùng cực tiểu, Gradient Descent sẽ tự động bước các bước ngày càng nhỏ bởi vì chúng ta đang hướng về khu vực tối ưu hóa với định nghĩa, cực tiểu là nơi đạo hàm bằng 0. Như vậy, khi chúng ta hướng về vùng cực tiểu, đạo hàm của hàm này sẽ tự động nhỏ lại và thuật toán sẽ dần hội tụ.
Xem thêm: Đăng Ký Otp Vietcombank – Đăng Ký Sử Dụng Ứng Dụng Vietcombank Smart Otp
Dưới đây là code để minh họa cho thuật toán :
def dL(X, y, theta): theta = theta.reshape(-1, 1) m = len(X) return -(1/m) * np.sum(X * (y – X
theta), axis=0)def gradient_descent(): m, n = X.shape # Khởi tạo theta ngẫu nhiên theta = np.random.randn(n) # Chọn các tham số như số lần lặp và hệ số alpha iterations = 1000001 alpha = 0.5 for i in range(iterations): # Cập nhật theta theo công thức của GD theta = theta – alpha * dL(X, y, theta) # Tính hàm mất mát loss = loss_multivariate(X, y, theta) if i % 20000 == 0: # Xuất giá trị mất mát ra để theo dõi print(“Iter {}. Loss = {}”.format(i, loss)) return thetaKết quả so sánh hàm mất mát giữa hai phương pháp:
Tuy nhiên, cũng sẽ có trường hợp mà Gradient Descent lại cho ra tác dụng tốt hơn trên tập test, hãy xem ví dụ sau :
# Chọn 1 điểm dữ liệu trong tập dữ liệu test và dự đoáni = 1x_1 = Xy_1 = y<0>hypothesis = x_1
theta_gdprint(“Dữ liệu của căn nhà cần dự đoán:\n”, x_1)print()print(“Dự đoán của phương pháp đầu tiên: {:.3f} (triệu USD)”.format(hypothesis))print(“Dự đoán của thư viện sklearn: {:.3f} (triệu USD)”.format(hypothesis_sklearn))print(“Dự đoán của gradient descent: {:.3f} (triệu USD)”.format(hypothesis_gd))print(“Giá trị thực tế: {:.3f} (triệu USD)”.format(y_1))Dữ liệu của căn nhà cần dự đoán: <1.000e+00 3.000e-06 2.250e-06 2.000e-06 0.000e+00 3.000e-06 7.000e-06 1.951e-03 2.570e-03 7.242e-03 2.170e-03 4.000e-04> Dự đoán của phương pháp đầu tiên: 0.709 (triệu USD) Dự đoán của thư viện sklearn: 0.632 (triệu USD) Dự đoán của gradient descent: 0.602 (triệu USD) Giá trị thực tế: 0.538 (triệu USD) Vậy là chúng ta đã xong phần lí thuyết cũng như hiện thực ý tưởng của Linear Regression thông qua Python và các thư viện. Để tham khảo thêm code minh họa cho thuật toán này, các bạn có thể tham khảo Colab Notebook mà mình đã chuẩn bị ở đây nhé!
6. Ứng dụng của Linear Regression trong thực tế
Dựa vào thuật toán này, chúng ta có thể sử dụng để giải các bài toán liên quan đến việc dự đoán mức lương trung bình sau khi ra trường dựa vào các đối số đầu vào là giới tính, điểm trung bình khóa học và số lượng các hoạt động ngoại khóa đã tham gia ,…
Hay trong các bài toán trả về giá trị nhiệt độ phòng với giá trị đầu vào là ngày, nhiệt độ ngoài trời và ánh sáng trong phòng, …
Cụ thể hơn và gần gũi với người dùng nhất, Facebook cũng sử dụng thuật toán này để dự đoán số lượng người share và bình luận dựa trên những tương tác trong bài viết trước đó của bạn hay số lượng bạn bè trên facebook, …
7. Tổng kết.
Như vậy, qua bài viết này, tất cả chúng ta đã tìm hiểu và khám phá về thuật toán Linear Regression, những khái niệm cơ bản cũng như cách ứng dụng nó vào trong những bài toán Dự kiến điểm Nhập môn Lập trình và Dự kiến giá nhà ! Mong là những bạn đã nắm rõ được lí thuyết và cách hiện thực sáng tạo độc đáo của Linear Regression .
Tuy nhiên, đây chỉ mới là thử nghiệm trên dữ liệu ta đã quan sát được, và kết quả chưa thể phản ánh chính xác mức độ hiệu quả của mô hình Linear Regression khi áp dụng vào việc dự đoán điểm nhập môn lập trình hay dự đoán giá nhà ngoài thực tế. Ở các bài viết sau của clb thì các bạn sẽ được giới thiệu thêm những phương pháp để đánh giá một mô hình khi đưa vào đời sống. Hãy đón đọc thêm các bài viết tiếp theo của chúng mình nhé!
Xem thêm: Đầu số 0127 đổi thành gì? Chuyển đổi đầu số VinaPhone có ý nghĩa gì? – http://139.180.218.5
7. Tài liệu tham khảo
Uyên Đặng – HTTT2019
Posted Under
Data Science Machine Learning Mathematics Optimization
Tagged
dự đoán giá nhà hồi quy đa biến hồi quy đơn biến hồi quy tuyến tính linear regression Machine Learning mathematics maths Máy học nhập môn lập trình
Các khái niệm cơ bản trong ngôn ngữ lập trình Python
Logistic Regression và bài toán phân loại cảm xúc âm nhạc
Leave a Reply Cancel reply
Your email address will not be published. Required fields are marked *\ mathcal { L } ( \ theta_0, \ theta_1 ) = \ frac { 1 } { 2 m } * \ sum_ { i = 1 } ^ { m }
Source: http://139.180.218.5
Category: Thuật ngữ đời thường