Nội dung chính
Data mining là gì?
Data mining là quy trình giúp trích xuất thông tin từ một tập tài liệu nhất định để xác lập khuynh hướng, mẫu và tài liệu có ích. Mục tiêu của việc này nhằm mục đích đưa ra những quyết định hành động được tương hỗ tài liệu từ những tập dữ liệu khổng lồ .

Data mining hoạt động giải trí cùng với predictive analysis ( nghiên cứu và phân tích Dự kiến ), một nhánh của khoa học thống kê sử dụng những thuật toán phức tạp được phong cách thiết kế để thao tác với một nhóm yếu tố đặc biệt quan trọng. Phân tích Dự kiến thứ nhất xác lập những mẫu trong lượng tài liệu khổng lồ, mà data mining sẽ tổng quát hóa cho những Dự kiến và dự báo. Data mining ship hàng một mục tiêu duy nhất, đó là nhận ra những mẫu trong tập tài liệu cho một tập hợp những yếu tố thuộc một domain đơn cử .
Ứng dụng của Data mining
Phân tích tài chính
Ngành kinh tế tài chính ngân hàng nhà nước dựa vào tài liệu chất lượng cao, đáng đáng tin cậy. Trong thị trường cho vay, tài liệu kinh tế tài chính và người dùng hoàn toàn có thể được sử dụng cho nhiều mục tiêu khác nhau. Như Dự kiến khoản thanh toán giao dịch khoản vay và xác lập xếp hạng tín dụng thanh toán. Và những giải pháp data mining làm cho những tác vụ như vậy dễ quản trị hơn .
Phát hiện xâm nhập
Kết nối toàn cầu trong nền kinh tế được thúc đẩy bởi công nghệ ngày nay đã đặt ra những thách thức về bảo mật đối với quản trị mạng. Tài nguyên mạng có thể phải đối mặt với các mối đe dọa và hành động xâm phạm tính bảo mật hoặc tính toàn vẹn của chúng. Do đó, phát hiện xâm nhập là một ứng dụng quan trọng trong việc khai phá dữ liệu.
Quản lý quan hệ khách hàng (CRM)
CRM ( Customer relationship management ) tương quan đến việc lôi cuốn và giữ người mua, cải tổ lòng trung thành với chủ và sử dụng những kế hoạch lấy người mua làm TT .
Phát hiện gian lận
Các hoạt động giải trí gian lận khiến những doanh nghiệp thiệt hại hàng tỷ đô la trong mỗi năm. Các giải pháp sử dụng để phát hiện gian lận quá phức tạp và tốn thời hạn. Data mining cung ứng một giải pháp sửa chữa thay thế đơn thuần .
Mọi mạng lưới hệ thống phát hiện gian lận lý tượng đều cần bảo vệ tài liệu người dùng trong mọi trường hợp. Một giải pháp được giám sát để thu thập dữ liệu và sau đó tài liệu này được phân loại thành tài liệu gian lận hoặc không gian lận. Dữ liệu này được sử dụng để giảng dạy một quy mô xác lập mọi tài liệu là gian lận hoặc không gian lận .
Các công cụ khai phá dữ liệu
RapidMiner
Tính khả dụng: Open source
RapidMiner là một trong những mạng lưới hệ thống nghiên cứu và phân tích Dự kiến tốt nhất được tăng trưởng bởi công ty có cùng tên. Nó được viết bằng ngôn từ lập trình Java. Nó cung ứng một môi trường tự nhiên tích hợp để deep learning, khai thác văn bản, máy học và nghiên cứu và phân tích Dự kiến .
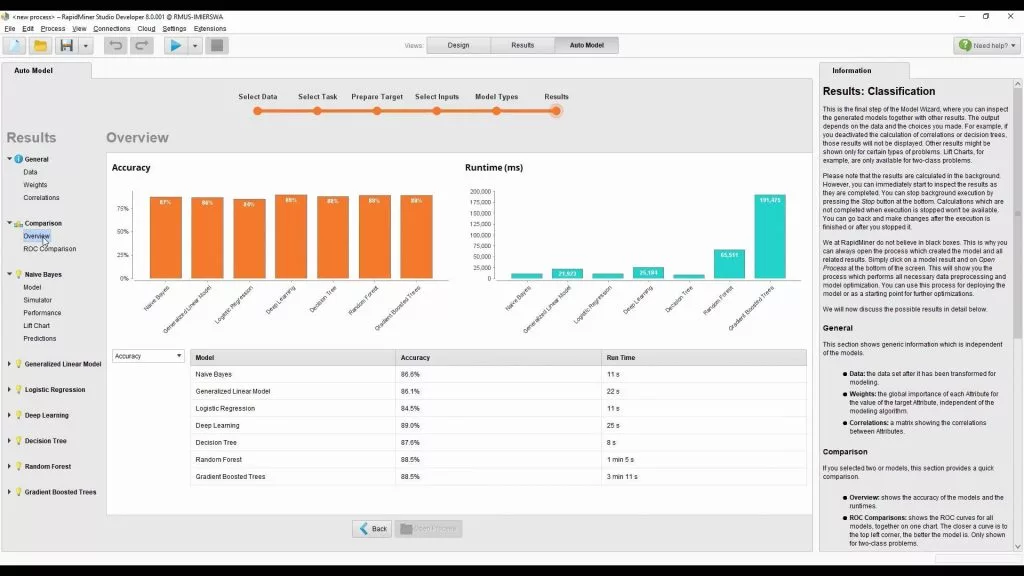
Công cụ này hoàn toàn có thể được sử dụng cho nhiều loại ứng dụng gồm có ứng dụng kinh doanh thương mại, ứng dụng thương mại, huấn luyện và đào tạo, giáo dục, nghiên cứu và điều tra, tăng trưởng ứng dụng .
RapidMiner cung ứng server on premise và trong hạ tầng private / public cloud. Nó có một quy mô client / server làm cơ sở của nó .
RapidMiner gồm có 3 module, đơn cử là :
- RapidMiner Studio: Module này dành cho thiết kế quy trình làm việc, tạo mẫu, xác thực, v.v.
- RapidMiner Server: Để vận hành các mô hình dữ liệu dự đoán được tạo trong studio.
- RapidMiner Radoop: Thực thi các quy trình trực tiếp trong Hadoop cluster để đơn giản hóa việc phân tích dự đoán.
Weka
Tính khả dụng Phần mềm miễn phí
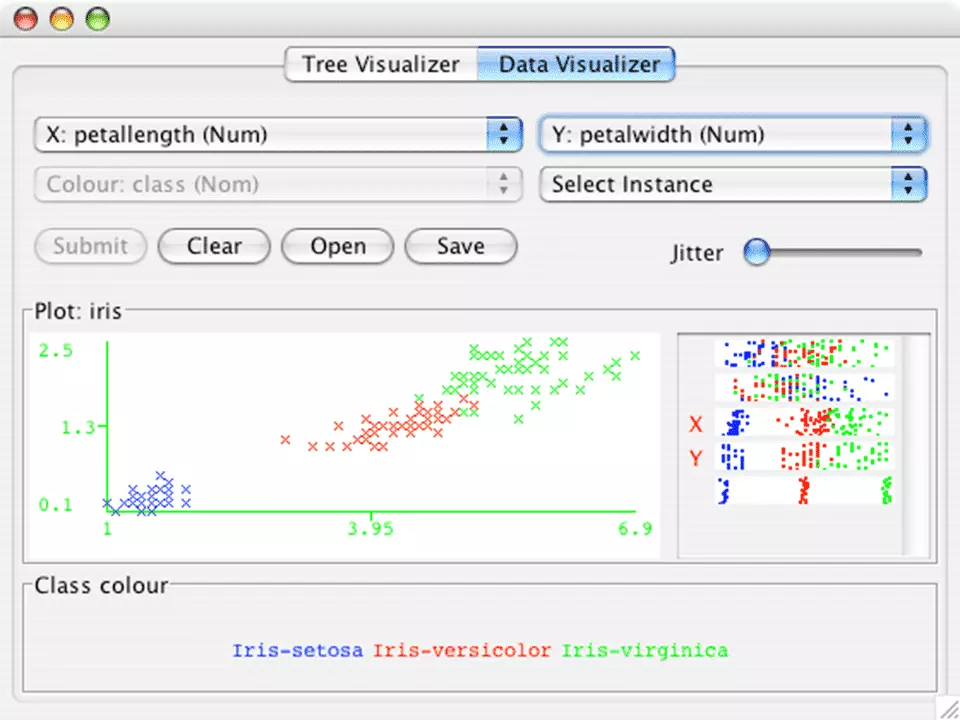
Còn được gọi là Waikato Environment. Đây là một ứng dụng học được tăng trưởng tại Đại học Waikato ở New Zealand. Nó tương thích nhất để nghiên cứu và phân tích tài liệu và quy mô Dự kiến. Nó chứa những thuật toán và công cụ trực quan tương hỗ học máy .
Weka có GUI tạo điều kiện kèm theo thuận tiện truy vấn vào những tính năng của nó. Nó được viết bằng ngôn từ lập trình Java .
Weka tương hỗ những tác vụ data mining gồm có khai thác tài liệu, giải quyết và xử lý, trực quan hóa, hồi quy … Nó hoạt động giải trí dựa trên giả định rằng tài liệu có sẵn dưới dạng flat file .
Weka hoàn toàn có thể cung ứng quyền truy vấn vào SQL database trải qua liên kết cơ sở tài liệu. Ứng dụng data mining này còn hoàn toàn có thể giải quyết và xử lý thêm tài liệu / tác dụng do truy vấn trả về .
KNime
Tính khả dụng: Open source
 KNIME là nền tảng tích hợp tốt nhất để nghiên cứu và phân tích và báo cáo giải trình tài liệu được tăng trưởng bởi KNIME.com AG. Nó hoạt động giải trí dựa trên khái niệm module data pipeline. KNIME gồm có những thành phần học máy và data mining khác nhau được tích hợp cùng nhau .
KNIME là nền tảng tích hợp tốt nhất để nghiên cứu và phân tích và báo cáo giải trình tài liệu được tăng trưởng bởi KNIME.com AG. Nó hoạt động giải trí dựa trên khái niệm module data pipeline. KNIME gồm có những thành phần học máy và data mining khác nhau được tích hợp cùng nhau .
KNIME đã được sử dụng thoáng đãng cho điều tra và nghiên cứu dược phẩm. Ngoài ra, nó hoạt động giải trí xuất sắc cho nghiên cứu và phân tích tài liệu người mua, nghiên cứu và phân tích tài liệu kinh tế tài chính và thông tin kinh doanh thương mại .KNIME có một số ít tính năng tuyệt vời như tiến hành nhanh gọn và lan rộng ra hiệu suất cao. Người dùng làm quen với KNIME trong thời hạn ngắn hơn và nó đã làm cho nghiên cứu và phân tích Dự kiến hoàn toàn có thể truy vấn được ngay cả những người dùng mới. KNIME sử dụng tập hợp những node để giải quyết và xử lý trước tài liệu để nghiên cứu và phân tích và trực quan hóa .
Apache Mahout
Tính khả dụng: Open source
Apache Mahout là một dự án Bất Động Sản được tăng trưởng bởi Apache Foundation nhằm mục đích ship hàng mục tiêu chính là tạo ra những thuật toán máy học. Nó tập trung chuyên sâu đa phần vào phân nhóm, phân loại và lọc cộng tác tài liệu .
Mahout được viết bằng Java và gồm có những Java library để triển khai những phép toán như đại số tuyến tính và thống kê. Mahout đang tăng trưởng liên tục khi những thuật toán được tiến hành bên trong Apache Mahout liên tục tăng trưởng .
Oracle Data Mining
Tính khả dụng: Giấy phép độc quyền
Là một thành phần của Oracle Advance Analytics, ứng dụng Oracle Data Mining phân phối những thuật toán data mining tuyệt vời để phân loại tài liệu, Dự kiến, hồi quy và nghiên cứu và phân tích chuyên biệt. Cho phép những nhà nghiên cứu và phân tích nghiên cứu và phân tích thông tin cụ thể, đưa ra Dự kiến tốt hơn, nhằm mục đích tiềm năng người mua tốt nhất, xác lập thời cơ bán hàng và phát hiện gian lận .
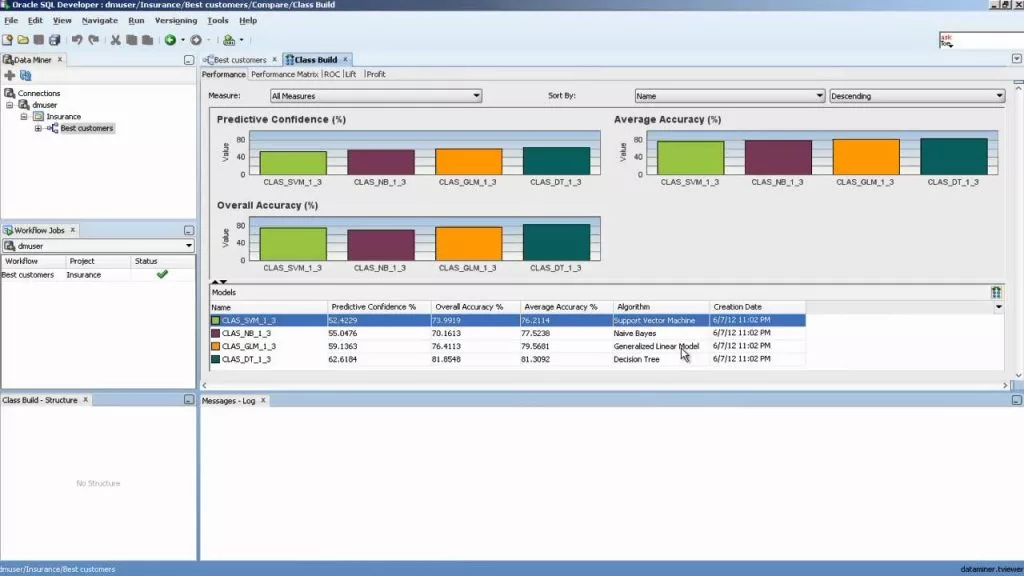
Các thuật toán được phong cách thiết kế bên trong ODM tận dụng những điểm mạnh tiềm năng của Oracle Database. Tính năng data mining của SQL hoàn toàn có thể đào tài liệu ra khỏi những bảng, dạng xem và lược đồ cơ sở tài liệu .
GUI của công cụ Oracle data mining là phiên bản mở rộng của Oracle SQL Developer. Nó cung cấp một phương tiện ‘drag & drop’ trực tiếp dữ liệu bên trong database cho người dùng, do đó mang lại cái nhìn sâu sắc hơn.
TeraData
Tính khả dụng: Được cấp phép
Teradata thường được gọi là database Teradata. Nó là một kho tài liệu doanh nghiệp chứa những công cụ quản trị tài liệu cùng với ứng dụng data mining. Nó hoàn toàn có thể được sử dụng để nghiên cứu và phân tích kinh doanh thương mại .
Teradata được sử dụng để phân phối thông tin cụ thể về tài liệu công ty như bán hàng, vị trí loại sản phẩm, sở trường thích nghi của người mua, v.v. Nó cũng hoàn toàn có thể phân biệt giữa tài liệu “ hot ” và “ cold ”. Có nghĩa là nó đặt tài liệu ít được sử dụng hơn vào phần tàng trữ chậm .
Teredata hoạt động giải trí trên kiến trúc ‘ share nothing ’ vì nó có những node server có bộ nhớ và năng lực giải quyết và xử lý riêng .
Orange
Orange là một bộ ứng dụng hoàn hảo nhất cho máy học và data mining. Nó tương hỗ tốt nhất cho việc hiển thị tài liệu và nó là một ứng dụng dựa trên component. Nó được viết bằng Python .
Vì nó là một ứng dụng dựa trên component, những thành phần của Orange được gọi là ‘ widget ’. Các widget này gồm có từ trực quan hóa và giải quyết và xử lý trước tài liệu đến nhìn nhận những thuật toán và quy mô Dự kiến .
Các widget cung cấp các chức năng chính như:
- Hiển thị data table và cho phép chọn các tính năng.
- Đọc dữ liệu.
- Đào tạo các công cụ dự đoán và để so sánh các thuật toán học tập.
- Trực quan hóa các phần tử dữ liệu, v.v.
Ngoài ra, Orange mang lại cảm xúc tương tác và mê hoặc hơn cho những công cụ nghiên cứu và phân tích khác .
Quy trình khai phá dữ liệu (Data mining)
Trước khi data mining xảy ra, có 1 số ít tiến trình tương quan đến việc data mining. Đây là cách thực thi :
Bước 1: Nghiên cứu kinh doanh – Trước khi bắt đầu, bạn cần hiểu đầy đủ về các mục tiêu của doanh nghiệp, các nguồn lực sẵn có và các tình huống hiện tại phù hợp với các yêu cầu của doanh nghiệp. Điều này sẽ giúp tạo ra một kế hoạch data mining chi tiết để đạt được mục tiêu của tổ chức một cách hiệu quả.
Bước 2: Kiểm tra chất lượng dữ liệu – Vì dữ liệu được thu thập từ nhiều nguồn khác nhau nên dữ liệu cần được kiểm tra và đối sánh để đảm bảo không có tắc nghẽn trong quá trình tích hợp dữ liệu. Việc đảm bảo chất lượng giúp phát hiện bất kỳ điểm bất thường cơ bản nào trong dữ liệu. Chẳng hạn như nội suy dữ liệu bị thiếu, giữ cho dữ liệu ở trạng thái tốt nhất trước khi trải qua quá trình data mining.
Bước 3: Dọn dẹp dữ liệu – Người ta thường dùng 90% thời gian dành cho việc lựa chọn, dọn dẹp, định dạng và ẩn danh dữ liệu trước khi khai thác.
Bước 4: Chuyển đổi dữ liệu – Bao gồm năm giai đoạn con, ở đây, các quy trình liên quan giúp dữ liệu sẵn sàng thành các file dữ liệu cuối cùng. Nó bao gồm:
- Làm mịn dữ liệu: Tại đây những dữ liệu bị nhiễu sẽ bị loại bỏ.
- Tóm tắt dữ liệu: Việc tổng hợp các file dữ liệu được áp dụng trong quá trình này.
- Tổng quan hóa dữ liệu: Tại đây, dữ liệu được tổng quát hóa bằng cách thay thế bất kỳ dữ liệu cấp thấp nào bằng các khái niệm hóa cấp cao hơn.
- Chuẩn hóa dữ liệu: Ở đây, dữ liệu được xác định trong các phạm vi đã đặt.
- Xây dựng thuộc tính dữ liệu: Các file dữ liệu bắt buộc phải nằm trong file hợp các thuộc tính trước khi data mining.
Bước 5: Mô hình hóa dữ liệu: Để xác định tốt hơn các mẫu dữ liệu, một số mô hình toán học được thực hiện trong file dữ liệu, dựa trên một số điều kiện.
Lời kết
Data mining tập hợp những chiêu thức khác nhau từ nhiều nghành nghề dịch vụ khác nhau, gồm có trực quan hóa dữ liệu, học máy, quản trị cơ sở tài liệu, thống kê và những chiêu thức khác. Những kỹ thuật này hoàn toàn có thể được triển khai để thao tác cùng nhau để xử lý những yếu tố phức tạp. Nói chung, ứng dụng hoặc mạng lưới hệ thống data mining sử dụng một hoặc nhiều giải pháp này để xử lý những nhu yếu tài liệu khác nhau, loại tài liệu, khu vực ứng dụng và trách nhiệm khai thác .
5/5 – ( 1 bầu chọn )
Source: http://139.180.218.5
Category: Thuật ngữ đời thường